【新興領域/2026.04焦點】AI霸權下的半導體技術革命,從原子級製程到光電一體化的深度轉型
2026年的全球半導體產業正處於一場前所未有的範式轉移,AI不僅是半導體市場的需求引擎,更成為推動技術邊界突破的核心動能,也就是當傳統的摩爾定律面臨物理與經濟的雙重極限,產業鏈正透過晶圓代工先進製程、先進封裝、記憶體階層重構、IC設計典範轉移,乃至於矽光子與量子運算的超前布局,建構出一套全新的AI時代技術體系。

2026年的全球半導體產業正處於一場前所未有的範式轉移,AI不僅是半導體市場的需求引擎,更成為推動技術邊界突破的核心動能,也就是當傳統的摩爾定律面臨物理與經濟的雙重極限,產業鏈正透過晶圓代工先進製程、先進封裝、記憶體階層重構、IC設計典範轉移,乃至於矽光子與量子運算的超前布局,建構出一套全新的AI時代技術體系。
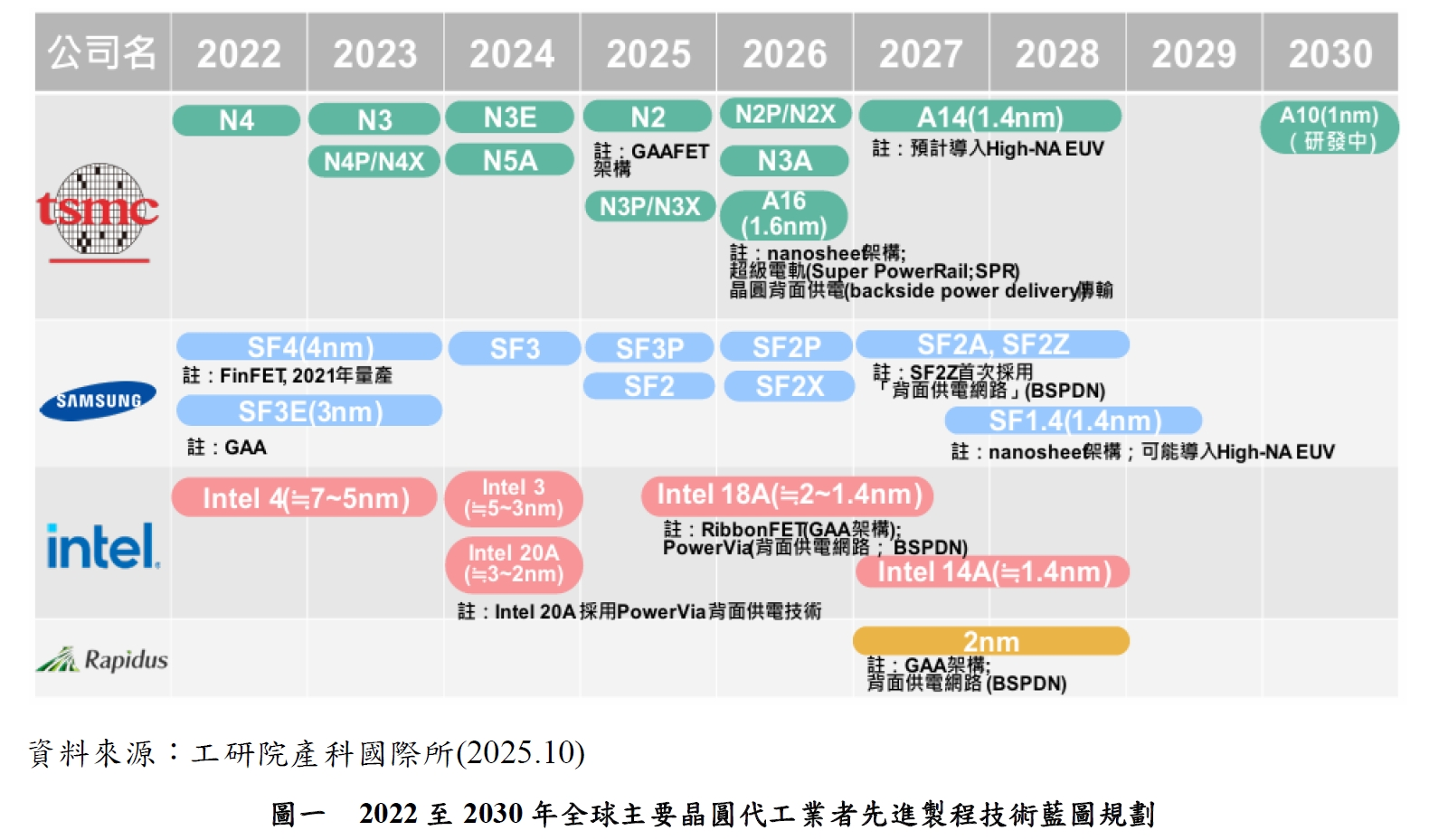
2026年台積電進入2奈米產能爬坡期,甚至爾後推出的A16、A14領先態勢將持續鞏固其在AI、HPC領域的領導地位
在晶圓代工領域,2026年代表奈米(Nanosheet)電晶體架構的全面普及與背面供電(Backside Power Delivery)技術的商業化元年,其中台積電作為領頭羊,其 2奈米製程正處於產能快速爬坡階段,這不僅是單純的尺寸微縮,更是一場材料與電路的革命;也就是為了滿足AI晶片對於超高頻率與低功耗的雙重渴求,背面供電技術如A16製程中的Super PowerRail,成功解決傳統前端佈線導致的壓降與散熱難題,使得電晶體密度在維持物理極限的同時,運算效能仍能獲得兩位數的成長;這場製程競賽的意義在於,只有掌握最先進節點的廠商,才能支撐起如Nvidia Rubin架構中那樣龐大且複雜的邏輯閘數量,進而確保在AI算力軍備競賽中的絕對話語權。
而根據圖一各業者於先進製程的推進方面,進入2026年,先進製程的競爭版圖已從單純的奈米節點微縮,演變為一場結合電晶體架構創新與電力傳輸效率的綜合軍備競賽;在這場競賽中,台積電憑藉著穩健的執行力與背面供電技術的領先,持續鞏固其在AI與高效能運算領域的霸權地位;Samsung則試圖透過Gate-all-around (GAA)架構的先行者優勢爭取訂單;而Intel則在五年五個節點的戰略衝刺下,進入檢驗轉型成效的關鍵決戰點。
作為全球晶圓代工的領航者,台積電在2026年正式進入2奈米製程的產能快速爬坡期,N2製程首度導入奈米片(Nanosheet)電晶體架構,相較於前代的FinFET,其在相同功耗下速度提升10~15%,或在相同速度下功耗降低25~30%;
然而,台積電更具戰略意義的推進在於A16製程的發表與量產預備,A16不僅是節點的微縮,更首度導入Super PowerRail背面供電技術;這項技術將原本複雜的電源線路從晶圓前端移往背面,徹底解決電路擁擠導致的壓降問題,對Nvidia 的下世代Rubin晶片或Apple的A系列處理器而言,代表晶片能以更高的頻率運行而不至於過熱,甚至台積電透過N2族群(包括N2P、N2X)與A16的組合,建構一道極高的技術障礙,讓客戶在尋求極致算力時幾乎沒有替代選項。
Samsung在先進製程的策略上採取激進跨代路線,也就是雖然Samsung在3 奈米節點就搶先導入環繞閘極(GAA)技術,但在2026年,Samsung面臨的核心課題在於良率穩定度與大型客戶的信任度;隨著其第二代3奈米與2奈米(SF2)製程的推進,Samsung正積極優化其電晶體性能與PPA(功率、效能、面積)指標。為了與台積電競爭,Samsung在2026年也同步推進其背面供電技術(BSPDN),並試圖將其與先進封裝(I-Cube、X-Cube)技術深度整合,提供一站式的解決方案;對於積極尋求非台積電替代方案的客戶(如部分ASIC設計商或手機晶片廠)來說,Samsung若能證明其2奈米GAA製程在良率上的突破,將有機會在AI晶片代工市場分得一杯羹,然而目前Samsung仍需在技術領先與大規模量產穩定性之間找尋平衡點。
Intel在2026年迎來其轉型歷程中最關鍵的一年,主要是其戰略核心Intel 18A製程已正式進入商業量產階段,這是Intel重返晶圓代工王座、爭奪外部客戶訂單的勝負手;18A製程同樣強調RibbonFET(其對GAA的稱呼)與PowerVia(背面供電)技;對Intel而言,18A的成功不僅關乎自家處理器的競爭力,更決定Intel Foundry Services是否能吸引到如Microsoft、Amazon等雲端巨頭的AI晶片訂單;Intel在2026年的推進尚包括更先進的High-NA EUV極紫外光曝光機的大規模應用;雖然High-NA帶來極高的成本壓力,但Intel寄望藉此在A14製程的研發上超車;依目前的觀察來看,Intel正努力克服代工模式下的服務轉型問題,若能順利量產18A並維持良率,將使全球先進製程市場從雙雄對決演變為三強共震的全新格局,但現階段要挑戰台積電強勢的領導地位仍相當困難。
綜合各業者的進度來看,2026年先進製程的推進已不僅是原子層級的蝕刻比賽,技術高度(如背面供電、GAA成熟度)固然重要,但與商業模式的結合才是最終決定市佔的關鍵;台積電憑藉著不與客戶競爭的純代工模式,在AI浪潮中收獲最豐厚;Samsung與Intel雖有自有品牌的垂直整合優勢,但在吸引外部客戶時仍面臨利益衝突與良率信任的挑戰;未來隨著製程向A14邁進,研發成本的指數級跳升將迫使業者在2026年更謹慎地選擇戰略盟友,這也預示著未來半導體產業將更趨向於由少數巨頭主導的系統級競爭。
從後段製程躍升為系統核心:先進封裝以異質整合突破光罩極限並定義AI運算終極效能、互聯密度與熱管理之戰,而2026年CoPoS與散熱技術將成為建構大規模AI基礎建設的勝負關鍵
2026年先進封裝的技術內涵已發生結構性轉變,當單一晶片的尺寸受限於光罩極限,產業界已不再執著於將所有功能塞進單一矽片,而是透過小晶片(Chiplet)架構,將原本龐大的處理器拆解為多個功能專一的晶粒台積電的CoWoS技術雖已建立堅固的市場壁壘,但為應對更嚴苛的成本與散熱挑戰,下世代的CoPoS(基板上面板晶片封裝)正成為新的戰略高地。
傳統CoWoS受限於矽中介層(Silicon Interposer)的尺寸與昂貴成本,難以無限制地擴大封裝面積,2026年推出的CoPoS技術,透過重布線層(RDL)與先進聚合物材料,繞過矽中介層的物理限制,不僅能整合更多的HBM記憶體,更大幅降低封裝厚度;這種技術演進使得Nvidia的Rubin架構能實現更驚人的互聯頻寬,將數個運算叢集視為單一實體運作,處理每秒數TB的資料流,解決AI訓練過程中的通訊延遲瓶頸。
事實上,2026年先進封裝正在將半導體價值鏈平台化,即透過將不同製程(如 3奈米的邏輯核心與7奈米的I/O單元)異質整合在同一個基板上,晶片業者能以更優化的成本結構實現頂級效能;封裝不再只是保護晶片,它更像是一個微型主機板,承載著精密的供電網絡與通訊架構;誰能掌握高良率、低成本的封裝技術,誰就能為全球雲端巨頭提供具備經濟規模的AI基礎建設,從而在這場算力競賽中維持長期的競爭優勢。
打破記憶體牆的雙軌革命:HBM鞏固大規模訓練基礎,而SRAM異軍突起重塑推論效能,顯然記憶體階層之權力重構主要是由於Nvidia結盟Groq導向雙軌制,為臺灣SRAM產業鏈開啟爆炸性商機
在2026年,AI晶片的競爭力已不再僅取決於算力,更取決於算力是否能被及時供給,也就是隨著模型參數突破數兆等級,傳統記憶體架構面臨前所未有的挑戰,為了徹底解決記憶體牆帶來的效能瓶頸,產業正在經歷一場從單一高頻寬轉向多層級分工的記憶體階層重構。
作為AI伺服器的核心心臟,HBM(高頻寬記憶體)已演進至HBM4世代,其中Samsung、SK Hynix、Micron在2026年投入史無前例的研發資本,試圖透過更多的堆疊層數(16層甚至更多)與更寬的數據通道(如2048-bit介面)來提升吞吐量;然而,HBM的生產良率極低、散熱壓力巨大且單價昂貴;儘管它是超大規模模型訓練的不可替代方案,但對於追求效率與低延遲的推論應用而言,HBM的存取延遲正成為效能更上一層樓的阻礙。
正是在這種背景下,Nvidia透過與Groq等新創公司的戰略結盟,推動SRAM(靜態隨機存取記憶體)在AI推論場景中的復興,Groq的LPU(語言處理單元)架構證明透過大量內建SRAM取代外部HBM,可以實現快上數倍的token產生速度;顯然在2026年的推論市場,SRAM負責即時決策路徑,能讓聊天機器人的回覆幾乎達到人類感知的零延遲,這種以空間換取時間的戰略,不僅提升使用者體驗,更大幅降低AI推論過程中的電力損耗,符合全球資料中心對綠色節能的嚴苛要求。
這場記憶體架構的雙軌制轉向,直接將臺灣的SRAM產業鏈推向風口浪尖,特別是由於美韓大廠在過去數年已將大多數資源轉向HBM開發,全球高品質、高密度SRAM的供應鏈重心意外地保留在臺灣;我國廠商憑藉著成熟的技術經驗與穩定良率,成為2026年Nvidia AI Factory平台中不可或缺的技術夥伴;這不僅意味著訂單量的倍增,更代表臺灣廠商正從傳統的記憶體供應商,轉型為協助客戶定義推論架構的關鍵參與者;當SRAM被視為與先進製程同樣重要的戰略資產時,臺灣記憶體產業正迎來一場結構性的價值重估與營收爆發期。
從單點效能轉向系統級互聯:臺灣IC設計業躍升全球AI自研晶片與矽光子標準之戰略建築師,其中聯發科領軍跨域整合新典範,台廠以軍火商身分定義算力殖民之新規則
在IC設計端,2026年見證從通用型設計轉向特定應用設計(ASIC)的大浪潮,雲端服務商如AWS、Google與Meta均在研發自主算力晶片,以擺脫對Nvidia 的依度依賴;然而Nvidia的反擊極具侵略性,它不僅僅銷售晶片,更透過AI工廠平台,將底層通訊協議(NVLink)標準化;這使得IC設計不再僅僅是邏輯設計,更涉及到金融資本與生態系的建構,特別是IC設計服務廠商如世芯與創意在2026年扮演著軍火商的角色,協助各大科技巨頭完成複雜的系統級開發;設計的重心已從單點效能轉向系統互聯效能,確保算力在成千上萬顆晶片集群中仍能維持高效率。
特別值得注目的,是聯發科在2026年的戰略飛躍,公司已成功從手機晶片領先者轉型為AI算力解決方案的全球領軍廠商,特別是聯發科利用其在行動裝置端積累的超低功耗與高性能運算經驗,結合與ARM及台積電的深度合作,積極切入資料中心ASIC市場;而2026年聯發科不再僅僅銷售晶片,而是提供一套完整的運算平台,透過整合其強大的通訊與影像處理技術,聯發科協助全球頂尖雲端廠設計具備極高能源效率的AI加速器,直接挑戰Qualcomm與Marvell在高效能運算領域的地位。
臺灣IC設計業者的另一項重要角色,在於對互聯技術的掌握,尤其是設計重心已從單點效能轉向系統互聯,臺灣廠商正積極參與矽光子與CPO(共同封裝光學)技術的標準制定,這意味著未來IC設計將與光學通訊、金融資本以及全球物流鏈深度掛鉤;臺灣業者不僅僅是在寫程式碼或劃電路圖,他們正在建構一套足以與Nvidia迴圈抗衡的開放式生態系。
整體而言,2026年的臺灣IC設計業正是掌握跨領域技術整合力的時期,無論是世芯與創意的精密代工設計,還是聯發科在AI算力平台上的霸權布局,臺灣企業已成功從參與者轉變為規則參與制定者,在這一場關於算力殖民與能源效率的綜合國力競賽中,臺灣IC設計產業正以其獨特的韌性與創新力,確保在全球AI數位轉型浪潮中,掌握最終的話語權。
光電融合與量子布局的技術突破點:半導體邁向AI算力殖民的新國力競賽,意謂從矽光子商用加速到原子級整合,等同掌握跨域整合力者方能定義數位未來規則
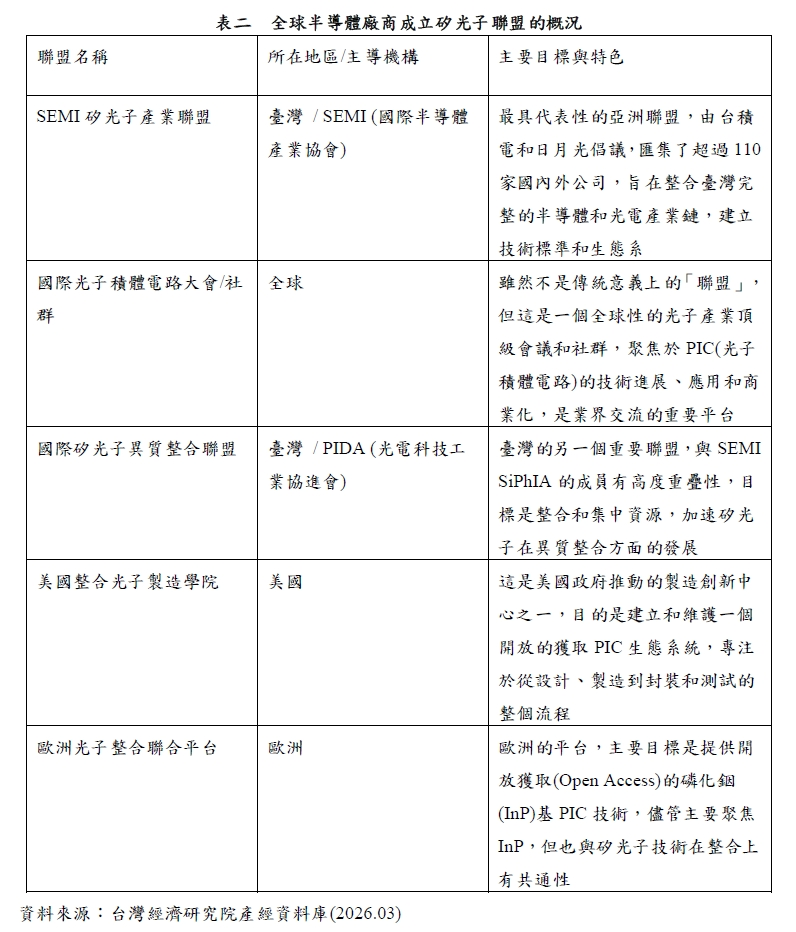
為了突破電信號傳輸的頻寬限制,矽光子(Silicon Photonics)技術在2026年正式進入商用加速期,透過光電整合的模式,資料傳輸不再依賴金屬導線,而是利用光纖進行高頻率交換,這項技術被視為解決資料中心功耗危機的終極方案;事實上,矽光子是下一代高速運算和數據傳輸的關鍵技術,全球各地都有主要的產業協會或機構成立聯盟來推動其發展和標準化(請參考表二),這些聯盟的核心工作都圍繞著解決矽光子技術在設計、製造、封裝、測試和標準化方面面臨的挑戰,特別是在AI和HPC時代對高頻寬、低功耗傳輸的迫切需求;台積電領銜的矽光子聯盟,正致力於將光學元件直接封裝在晶片旁,實現近乎零損耗的高速通訊。
最後,對於更遠未來的量子運算(Quantum Computing),半導體界也開始原子級的整合布局,雖然量子電腦尚處於發展早期,但其所需的低溫超導環境與精密量子邏輯控制,正借用半導體成熟的微細加工技術進行原型製作;2026年的產業界已意識到,AI的終極算力可能來自於量子力學與半導體製程的結合,這將是下一個十年的技術制高點。
AI霸權下的半導體奇點革命:從原子級製程到光電運算的國力競賽,來重塑全球算力殖民的新秩序,等同掌握跨域整合力者方能定義數位未來規則
隨著2026年的到來,AI不再僅僅是科技產業的一個分支,它已演變成一場波瀾壯闊的技術革命,徹底重塑從材料物理到系統架構的每一層邏輯,也就是半導體產業正處於一個關鍵的技術奇點,其核心特徵在於運算力、能源效率與通訊頻寬三者之間的深度融合,這場變革不僅限於晶圓代工,更延伸至先進封裝、記憶體階層重構、IC設計服務,乃至於更具前瞻性的矽光子與量子運算領域。從另一個層面來看,2026年半導體產業技術的革新已不再是單打獨鬥,從台積電的製程領先,到Nvidia的資本與標準統治,半導體已成為一場關於算力殖民與能源效率的綜合國力競賽。AI驅動的技術革命,正迫使我們重新審視從原子結構到全球物流的每一個環節,唯有掌握跨領域技術整合力的企業,方能在這場波瀾壯闊的數位轉型中,成為最終的規則制定者。





