【新興領域/2024.08焦點】模型界的大胃王!人工智慧快速發展下面臨的數據問題
今年年初,人工智慧的相關話題因為生成式技術而快速傳遍大街小巷,生成式AI在短時間內在各種層面上創下紀錄,包括推動整體人工智慧領域在募資環境嚴峻的2023年創下亮眼成績;科技巨頭爭先恐後併購擁有該技術的新創,就怕晚了一步便會跟不上它的車尾燈;以及一筆接著一筆的鉅額投資落入生成式AI新創公司囊中。本文透過生成式AI發展趨勢,解析隨之而來風險與機會,並介紹藉此趨勢崛起的新創企業。
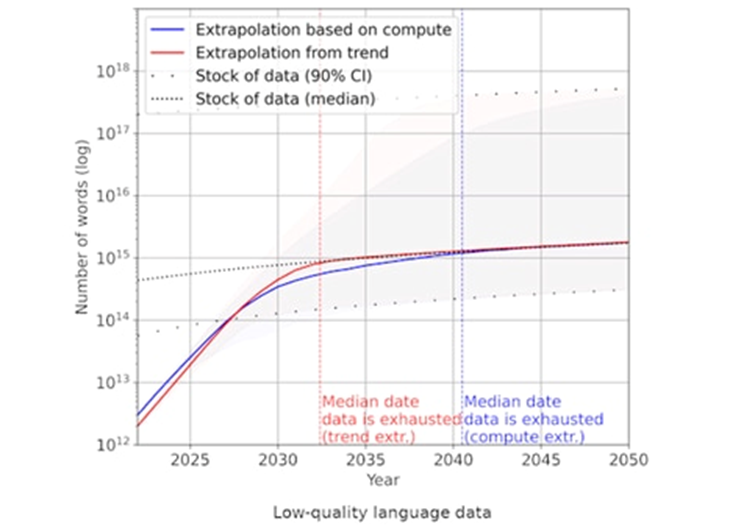
資料來源: Will we run out of data? Limits of LLM scaling based on human-generated data
激情過後,生成式AI催化產業的新型態,在Generative AI年會上,簡立峰教授指出「用AI的人正在取代不用的人,用AI的企業也正在取代不用AI的企業,這不僅是個別現象,更是國家間科技實力的較量。」,假如沒有跟好這輛特快車,那麼將隨時被潮流淘汰,技術的快速發展肉眼可見,我們所身處的生活與工作環境也漸漸有生成式AI的介入。然而,人工智慧需要仰賴高品質的數據資料來訓練,考慮到安全性與機密問題,許多有用資料在使用上受到限制,另一方面,免費的網路資源也不再是取之不竭、用之不盡,據Pablo Villalobos 等人的研究,到了2026年我們將會耗盡高品質的語言數據庫存,接著便是視覺媒體數據的耗盡,此趨勢會大大減緩人工智慧的發展速度。
主動防禦,化危機為轉機
人工智慧的指數級成長迎來前所未有的技術進步時代,大型語言模型(LLM)的快速發展和對於通用型人工智慧(AGI)的追求越發熱烈,加劇人們對個人資料蒐集、存取和利用的擔憂,「資料隱私」成為迫在眉睫的關鍵問題。LLM的發展與大量資料的取得及處理密不可分,要能做到生成文本、圖像和影音,進行自然語言處理,甚至是表現出推理與創造的功能,背後得消耗大量的線上文章、書籍和社交媒體的貼文紀錄等資訊,而其中大部份資料包含個人或企業的敏感資料,企業規劃將生成式AI工具納入產出流程的同時,因為缺乏對技術的瞭解而將機敏資料輸入模型,造成數據流出、系統中毒以及被攻擊等事件層出不窮,無論是開放式、封閉式的LLM皆面臨資料外洩以及生成輸出遭濫用等威脅,為了解決隱私安全,面向保護機器學習模型的新創公司開始嶄露頭角。
- HiddenLayer
將人工智慧應用於網路安全的技術越來越多,但仍屬於較新的領域,多數產品能保護用戶的系統,卻沒辦法保護人工智慧系統本身,而HiddenLayer在這樣的背景下悄悄崛起,2022年7月獲投600萬美元的種子輪,用於開發機器學習偵測與回應平臺(MLDR)。HiddenLayer發現企業常在不知不覺間在模型中創造漏洞,而這些漏洞沒有良好的安全措施能保護,於是該公司使用模型來保護模型,HiddenLayer可以偵測到四種主要類型的針對模型的攻擊:推理、資料中毒、竊取和迴避,每分鐘分析數十億次模型運算,以偵測惡意活動,保護智慧財產權和商業機密免遭盜竊或篡改,並確保使用者不會受到攻擊。
HiddenLayer在募得種子輪後接連與Databricks和Intel建立合作夥伴關係,並分別獲得RSAC的「最具創新性新創公司」和SC Media 的「最有前途的早期新創公司」等殊榮,前述兩項皆為網路安全界的大規模活動,一舉提高行業認可度,2023年9月獲得由M12, Microsoft's Venture Fund和Moore Strategic Ventures等領投的5,000萬美元A輪募資,2024年5月宣布Microsoft Azure AI成為其產品Model Scanner的新用戶,用於掃描Azure AI中第三方和開源模型,驗證其不存在網路安全漏洞、惡意軟體和其他竄改痕跡,開源模型因其經濟性和靈活性而受到青睞,但其極容易受到惡意利用,透過HiddenLayer的產品,Azure AI 可以幫助安全團隊簡化 AI 部署流程,並使開發團隊能夠更自信地安全地微調或部署開放模型。
- CalypsoAI
CalypsoAI的創始人為政府部門出身,在政府內部建構人工智慧時經常因為模型無法驗證其安全性,造成專案停擺或是被放棄,其創始人便離開政府並成立CalypsoAI,旨在提供人工智慧效能、可靠性和安全性的驗證,為國家安全、金融和其他高度監管行業領域的客戶提供服務。2023年6月CalypsoAI獲由Paladin Capital Group領投的2,300萬美元A輪募資,該公司聲稱其研發的產品能夠提供企業透過儀表板監控和調整如ChatGPT等大型語言模型的使用情況,將能夠掌握模型的不安全性、使用者參與度等相關數據,且可以做到防止機敏資訊在模型上共享並同時識別來自生成式AI的攻擊。即便許多公司已經明文禁止在公司內部使用生成式AI工具,模型安全的仍具有極大潛在市場。
- DeepKeep
DeepKeep起初致力於保護物件偵測和臉部辨識的電腦視覺模型,現在,它可以承諾電腦視覺、LMM和多模態模型等的健康及穩定性。該公司成立於2021年,並在2024年1月獲由VC Awz Ventures領投的1,000萬美元種子輪,同時推出AI原生(AI-Native)信任、風險和安全管理平臺TRiSM,隨著人工智慧在各個垂直領域的採用劇增,可能遭受的攻擊面也在擴大,DeepKeep表示,其與模型無關的多層平臺可以保護人工智慧從研發到部屬的整個過程,該平臺已被全球人工智慧運算、金融、安全等行業企業廣泛使用,涵蓋風險評估、檢測、緩解和預防,如近期採訪中CEO分享其對Meta LlamaV2 7B LLM進行評估,並總結LlamaV2 7B 模型展示其在任務績效和道德方面的優勢,在處理複雜轉換、解決偏見和針對複雜威脅的安全性方面還有待改進。隨著與跨國企業的合作,對多種語言支援的需求不斷增長,DeepKeep計畫擴展多語言的自然語言處理。
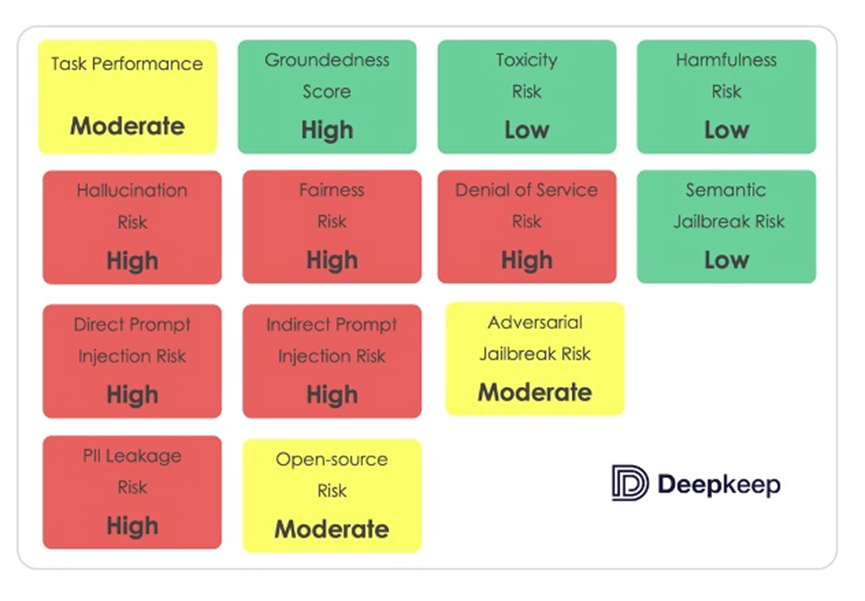
註:DeepKepp對Meta LlamaV2 7B LLM進行各項風險評估
資料來源: DeepKeep
大數據時代即將迎來盡頭?
人工智慧模型的效能來自於大量的數據,還得是高質量的數據才能發揮作用,例如社群軟體上的貼文與低畫素的圖像雖然獲取容易,卻不足以訓練高性能的模型,甚至可能使其產生偏見與虛假、非法資訊的產生。起初以網路資源做為模型的訓練素材看似非常理想,人類文明發展至今在網路、生活中累積了大量數據,這些免費的材料促進文本、圖像與影音模型的發展,然而,自2023年初以來圍繞著數據使用的糾紛與限制探出頭,免費的網路資源不再是優勢,高品質的專有數據取得更是難上加難。
回頭看2023年,1月Getty Images對Stability AI提出訴訟,指控其濫用平臺中超過1,200萬張圖像來訓練其圖像生成模型,其事件在當下引起生成式模型訓練素材來源的熱議,判決一路持續到12月,英國法院裁定其可以進入審判階段,而Getty Images也不是當時唯一向人工智慧企業提出版權訴訟的視覺藝術創作者;3月X(原:Twitter)宣布新的API定價,包括對五萬筆推文收取約4.2萬美元的企業級訪問費,以及面向新創公司每月5,000美元的方案,能夠獲取100萬筆推文及發布30萬筆推文,並允許其擁有完整的搜尋端點存取權,即使推出介於基本方案與企業方案間的價位,仍有許多研發人員表示每年需要支付6萬美元的價格仍有負擔;網路大型論壇Reddit也成為Google、OpenAI和微軟等公司開發LLM工具的資源,隨著論壇做為訓練數據的價值水漲船高,Reddit於6月宣告收取每1,000次API呼叫0.24美元的價格,此舉不僅引起大量抗議,也放大存取受限將阻礙創新並限制LLM持續進步的問題;最後,於12月《New York Times》對OpenAI和微軟起訴,指控其未經授權使用已發表的內容來訓練模型的行為是侵犯版權,且聲稱這些被訓練出來的模型正在和新聞媒體競爭,雖然訴訟不包括確切的賠償要求,但其主張OpenAI與微軟應對「非法複製和使用獨家報導作品」的相關損失負責,並呼籲公司銷毀使用到這些數據的模型和訓練資料。
在技術變革的時刻,版權的邊界經常受到新的挑戰,而人工智慧的迅速成長更是讓解決方法跟不上問題出現的速度,科技業對於版權問題也皆有自己的立場,認為讓人工智慧承擔版權責任是扼殺技術的發展。隨著網路資源的成本及限制抬高,擁有流量與大量文本、圖像數據的公司也將有可能因此成為被併購的對象,縱使數據品質對模型的優化很重要,但存取大量的資訊仍是模型建置的關鍵因素。
利用生成式技術來創造訓練數據

資料來源: Boost PII Detection: How LangChain’s Synthetic Data Enhances AI Training
除了老實支付取得訓練數據的成本,另一項屬於生成式AI催生的領域「合成數據」也開始獲得關注,既然現實世界的資料數據浮現稀少性的問題,不如就利用生成式AI的生成功能創建各種合成數據,NVIDIA於今年6月推出開源模型Nemotron-4,開發者可藉由模型生成合成數據建置強大的LLM,且該模型家族支援醫療照護、金融、製造、零售和其他領域的商業應用,其中,Nemotron-4 340B的基礎模型在9兆個Token上進行訓練,可利用NeMo框架進行客製化,以支援特定領域;而指令模型則是用來創建模仿真實世界資料特徵的各種合成資料,以提高不同領域的資料品質;再利用獎勵模型進行過濾,進而獲得更高品質的回應,Nemotron-4 340B的3種模型建立了一個管道,以生成及優化用來訓練LLM的合成資料。
透過使用乾淨的數據來生成合成數據,企業能大幅少數據團隊的傳統工作量,也就是最繁瑣的資料清理及萃取有用資訊,一舉解決資料科學家的短缺以及數據用盡的危機,合成數據的優勢大致上包括下表四點:
表1:合成數據的四大優勢
|
優勢 |
應用內容 |
|
符合成本效益 |
在現實情況下,蒐集與對資料下註釋的成本極高且耗時,對於某些特定領域的人工智慧模型來說,能夠以較低的成本產生合成數據,可能是唯一獲取大量訓練資料的方法 |
|
資料強化 |
透過合成數據增加資料集的大小和多樣性,模型有機會學習泛化並做出更準確的預測,可擴大數據的維度又可以提供機器學習的效能 |
|
隱私保護 |
醫療紀錄與財務紀錄等機敏資料包含大量個人隱私,透過生成技術,合成數據能擁有與原始資料相同的統計特性,同時忽略實際個人資訊,在不損害隱私的情況下與第三方共享資料並貢獻於模型訓練 |
|
場景生成 |
合成數據能夠模擬現實世界中難以觀察到的場景,如:用於模擬測試自動駕駛汽車在各種駕駛場景中的安全性,無須進行昂貴且耗時的實際測試,透過創建涵蓋廣泛的場景和各種可能性的組合能夠協助開發更複雜、準確的偵測模型。 |
合成數據又分為三種方式,分別是完全透過模型產出的完全合成數據,能完全解決和隱私問題相關的情境;部分資料集以合成數據替換的部分合成數據,保留現實情況特徵並在隱私問題中取得平衡;以及將現實數據與合成數據結合的混合合成數據,目的在於結合兩種數據的優勢創造多樣化的資料集,各行業在導入生成式技術不免遇到機敏資料和數據不足兩大困擾,合成數據領域的新創便成為最理想的合作夥伴,作為工具能夠讓自家公司跟上人工智慧模型的熱潮又不用擔心資料外流或是需要支付昂貴成本,以下介紹經本研究整理,在各行業專攻合成數據的新創公司。
資料來源: MOSTLY AI
- MOSTLY AI
MOSTLY AI於2017年由Michael Platzer、Klaudius Kalcher和Roland Boubela領導的奧地利資料科學家團隊創立,致力於超越數據匿名化,透過合成數據技術解決企業運用數據所面臨的隱私障礙,用戶可於MOSTLY AI平臺上傳自家資料,平臺也有提供範例資料,接著便能依照操作指南進形合成數據,為了衡量合成數據集的品質,MOSTLY AI提供品質保證報告,內容包括詳細的準確性指標,捕捉合成數據遵循原始數據分布的程度;用戶若需要與第三方共享數據,可以提高數據隱私等級設定,使合成數據與原始數據的距離較遠,如果數據僅在公司內部共享,則可以優先考慮準確性並保留滿足監管與合規準則的隱私等級。2022年1月MOSTLY AI獲得2,500萬美元的B輪募資,並已與北美和歐洲的多家財富100強銀行和保險公司合作。
- Hazy
Hazy成立於2017年,其合成數據平臺能大規模產出合成數據,並在不損害用戶隱私的情況下產出和輸入資料相同統計屬性與結構的數據,其生成模型打破一對一的數據點映射,依靠生成式機器學習產生資料,首先以真實資料做為輸入,更新模型參數與學習資料形態,輸出模型;接著,對模型進行採樣以合成資料集,取代單一真實資料點到單一合成資料點的一對一映射,結合該企業擁有的隱私技術,滿足刪除與個人相關的任何訊息,並做到減少資料連結到原始資料的機會,避免原始資料受到攻擊。
截至2023年3月,Hzay透過六輪募得近1,500萬美元的獲投金額,2024年3月Hazy和Unbanx宣布合作,金融交易資料對許多金融機構在提供消費者行為和趨勢資訊而言非常重要,然而,這些資料經常在未經同意的情況下遭出售及使用,Unbanx聲稱銀行一直在悄悄將客戶銀行數據出售給數據分析行業,為了改變該現況Unbanx設置讓一般用戶能夠自行選擇匿名出售自己的消費者資料,並獲取70%銷售利潤的應用程式,透過和Hazy合作,推出基於這些消費數據的金融合成數據,旨在提供更多過去因為監管或隱私限制而無法存取的數據形態,兩間企業對數據的理想一拍即合,促成此次合作。
- Tonic.ai
工程師在建立軟體時經常在不使用用戶實際資料的情況下測試軟體遇到問題,而創建具備實際情況的模擬資料集過於耗時且有一定的門檻,Tonic.ai便正在專為工程師生成合成數據。Tonic.ai成立於2018年,推出Tonic Structural,用於資料去識別、合成和配置的開發者平臺,使開發者能夠在測試和開發環境中保持測試資料的安全、可存取和同步,該公司的CEO聲稱雖然同時期有其他合成數據的新創正在運作,但是並沒有人真正解決企業的數據問題,如繁瑣的數據基礎設施作業與CI/CD流程(自動化測試與自動部暑),這些是Tonic.ai有別於其他新創的地方,2021年9月獲得由Insight Partners領投的3,500萬美元B輪募資。
2024年6月Tonic.ai在Snowflake Marketplace上推出Tonic Textual,並入選由Notable Capital推出Rising in Cyber 2024,旨在表彰最有前途的網路安全公司,利用其在資料管理和現實合成方面的專業知識,Tonic Textual可以在嵌入、微調或資料庫擷取之前將孤立且混亂的非結構化資料進行轉換及保護隱私,生成能夠訓練人工智慧模型的格式。
- Replica Analytics
同樣是合成數據的新創,Replica Analytics專為健康醫療領域的提供技術,同時滿足建模和疾病分析對高品質數據的巨大需求,公司創立初期募得100萬美金的Pre-seed輪,其中在2021年與Aridhia建立合作關係,將Replica Analytics的資料合成解決方案與Aridhia 的數位研究環境(DRE)整合。合併後的產品為提供用戶以合規的方式快速配置及使用合成數據;接著在2021年底被Aetion收購,該企業為健康醫療領域的分析公司,為醫療領域和監管機構等客戶提供真實世界證據(Real-world evidence; RWE),其由哈佛醫學院的教員創立,在傳染病學和健康結果研究方面擁有數十年的經驗,為醫療保健領域最關鍵的決策(什麼最有效、最適合誰以及何時)提供資訊,以指導產品開發、商業化和支付創新,該公司收購Replica Analytics用於生成醫療領域的合成數據;2023年Replica Analytics再度與Aridhia建立新的合作關係,推出完整且保護隱私的資料共享解決方案,Aridhia提供的資料共享平臺受到醫療研究機構、製藥業和全球財團的信任,透過此次合作減化內部或跨公司、跨國際的協作分析環境設置,資料管理人可以更精細的控制資料的存取、生成和共享方式,
2024年4月,Replica Analytics正式更名為Aetion® Generate,整合後持續在Aetion旗下創建合成數據。
結語
高品質數據的需求迫使開發人員及企業開始思考各種應對措施,負擔得起成本的企業開始考慮使用免費線上資源以外的內容,如訂閱大型出版社與資料庫的內容、直接收購擁有珍貴專利資料的公司,甚至是使用自家公司的客戶資料,如Meta在今年4月經報導指出正在考慮收購出版社Simon & Schuster,用來培訓自家的人工智慧工具,然而這樣的意圖必引起文學著作擁護者的反彈;據《Times》報導,Google正在考慮將免費版用戶的Google Docs、Google Sheets、Google Slides,甚至Google Maps上的餐廳評論中用來訓練模型,雖然至今仍未公告已在模型中使用用戶資料。
在另一方面,考慮了成本與規範,合成數據開始成為企業的下一個目標,OpanAI執行長曾在2023年的一次會議上表示只要模型效能足夠,便能生成合適的合成數據,也將解決數據稀缺的問題,至今也已經有使用合成數據訓練的LLM釋出,生成式AI和合成數據的組合將進一步改變以往熟知的資料框架,這些技術從資料稀缺、隱私問題和監管合規等關鍵問題中釋放人工智慧發展的新潛力,儘管它也帶來了道德困境、潛在安全風險和資料品質擔憂等挑戰。
宏觀而言,這項技術不僅為推動人工智慧提供一條充滿希望的途徑,也有機會重塑產業,使其更有效率且合乎規範的運作,透過合成數據,醫療、金融和政府等高安全等級的領域可以在不損害隱私的情況下增強發展,無論如何,面對人工智慧的大胃口,各種替代方案已經是進行式,若持續以熱情並謹慎的態度開發解決方案,則能有望人工智慧的發展繼續造福社會。
參考資料
- HiddenLayer Emerges From Stealth With $6 Million to Protect AI Learning Models https://www.securityweek.com/hiddenlayer-emerges-stealth-6-million-protect-ai-learning-models/
- HiddenLayer Raises $50M in Series A Funding to Safeguard AI https://www.prnewswire.com/news-releases/hiddenlayer-raises-50m-in-series-a-funding-to-safeguard-ai-301931260.html
- CalypsoAI raises $23M to add guardrails to generative AI models https://techcrunch.com/2023/06/27/calypsoai-raises-23m-to-add-guardrails-to-generative-ai-models/
- DeepKeep: An Interview With Founder And CEO Rony Ohayon About This Fast-Growing AI Security Company https://pulse2.com/deepkeep-rony-ohayon-profile/
- Top 10 Synthetic Data Generation Companies Revolutionizing the industry https://www.linkedin.com/pulse/top-10-synthetic-data-generation-companies-revolutionizing-ossec/
- Top 15 Synthetic Data Companies for Your Business in 2024 https://www.questionpro.com/blog/synthetic-data-companies/
- Crunchbase https://www.crunchbase.com/





